
Which models are the most HIP?
Frontier models wrote HIP kernels for KernelBench on MI300X. We measured which ones were correct and how fast.

Frontier models wrote HIP kernels for KernelBench on MI300X. We measured which ones were correct and how fast.
LLM-generated kernels are all the rage right now. Over the past year, models have gone from struggling with basic CUDA syntax to producing code that can rival hand-tuned implementations.
But almost all of that progress has been centered around NVIDIA, with most public benchmarks focusing on LLM’s ability to write CUDA kernels. AMD’s MI300X is competitive on paper (192GB HBM3, 5.3 TB/s bandwidth), and yet a lot of real-world stacks still leave performance on the table. The problem is that AMD kernels are written in HIP, not CUDA, and the optimizations that work for NVIDIA break down when writing kernels for AMD.
With increasing reliance on AMD hardware from large companies such as Meta, it is becoming increasingly important for AMD’s inference software ecosystem to catch up with NVIDIA. LLM-generated HIP kernels could help close the software gap. It also makes it easier to test new architectures without being bottlenecked on kernel engineering ability. The question is: can today’s models actually write fast, correct kernels for MI300Xs?
To answer that question, we used KernelBench, a benchmark suite created by Stanford’s Scaling Intelligence Lab for evaluating LLM-generated GPU kernels. It contains problems across four difficulty levels, ranging from simple operations to complex fused kernels. We credit Elliot Arledge specifically for creating a representative subset of these kernels designed to resist reward hacking.
We gave models from six providers the same task: optimize each kernel for MI300X. We measured two things: correctness (does the kernel produce the right output?) and speedup relative to KernelBench’s reference implementations.
The models tested were Claude Opus 4.5, GPT-5.2, Gemini 3 Pro, Gemini 3 Flash, Grok 4.1, Kimi K2, and GLM 4.7 (current leading OSS models). For Opus, GPT, and GLM, we also compared high-thinking and low-thinking modes. For these benchmarks, we limited tool access to bash and write.
Our benchmarks were run in the following environment:
- OS: Ubuntu 24.04.3 LTS
- GPU: AMD MI300X
- ROCm Version: 7.0.0
- PyTorch: 2.9.0
Results + Discussion
We are fully open sourcing our traces. Explore them interactively in the benchmark results explorer below, or browse the raw data on GitHub.
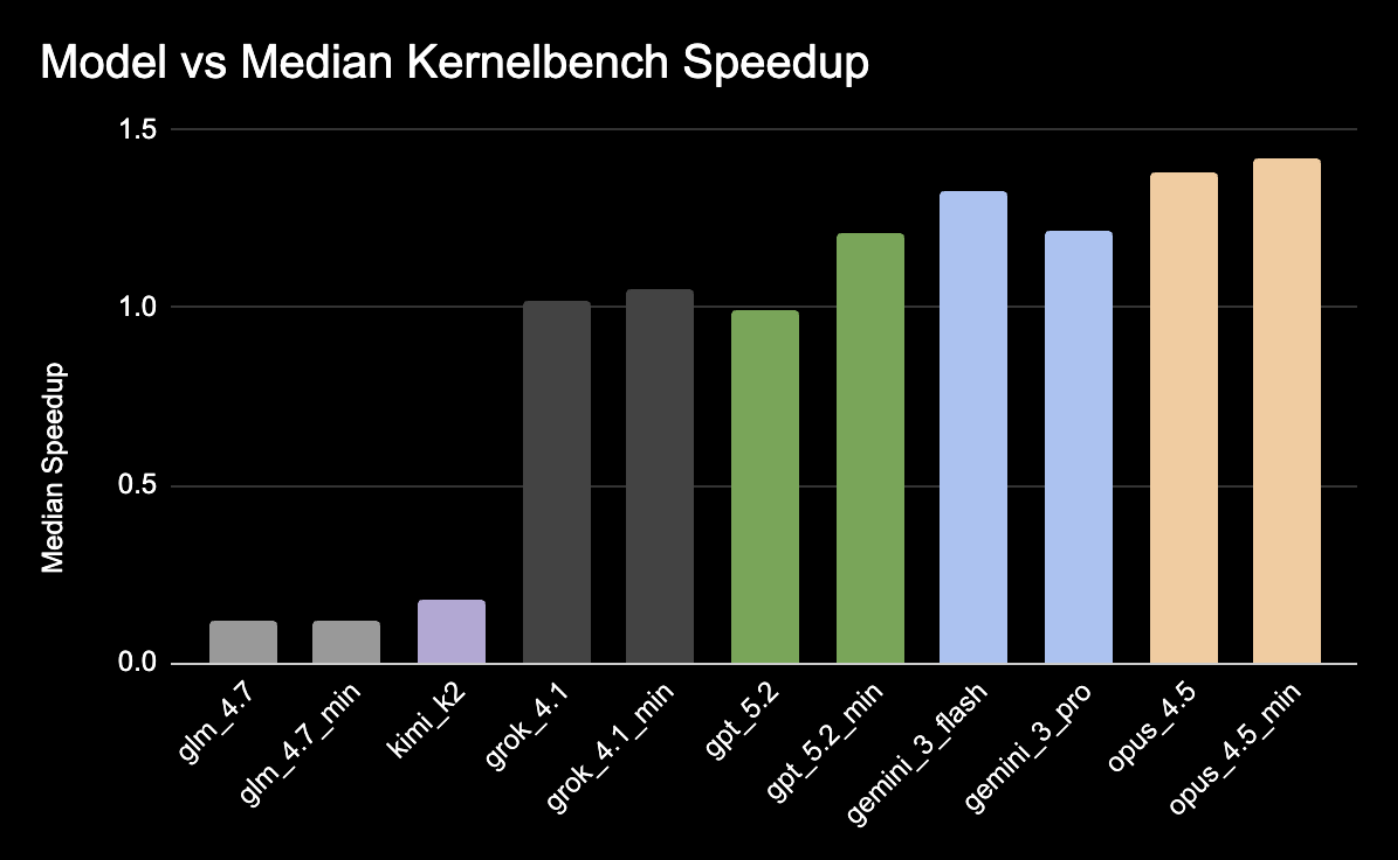
From our benchmarks, models generally did a solid job at optimizing the KernelBench problems, with GPT, Gemini, and Opus consistently beating reference implementations.
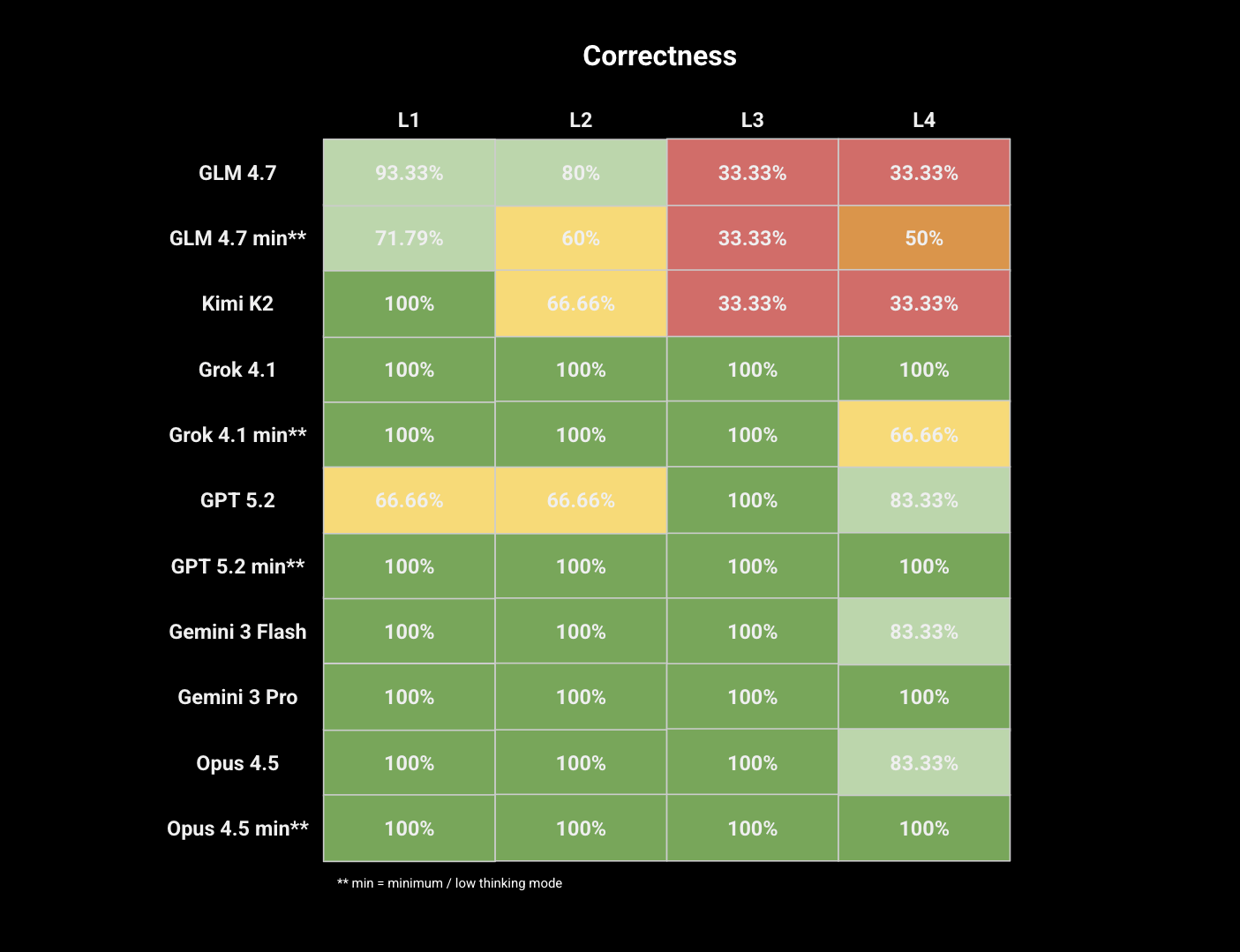
The most obvious result is that leading OSS models struggle greatly at writing HIP kernels compared to the closed source models, with GLM and Kimi consistently either failing correctness checks or writing HIP kernels slower than baseline. Surprisingly, the closed source models achieved correctness very consistently. In general, these models achieved correctness very quickly, with the median turn for correctness being 3 and the most common turn for correctness being turn 2. This implies that models can generally one-shot correct HIP code, a very promising result.
Another surprising result is the minimal difference between max-thinking and min-thinking models: min-thinking performed as well as max-thinking across the board, often outperforming them. This suggests that for HIP kernel generation, model knowledge matters more than extended reasoning; either the model has seen the right patterns or it hasn’t.
Models typically struggled at finding optimizations in simpler KernelBench L1, not surprising given that simpler kernels are already heavily optimized for MI300s, and tended to perform much better given more complex/fused kernels, giving over 10x speedup for some kernels. Notably, GPT 5.2 achieved 28.95x on GatedDeltaNet, and Opus 4.5 achieved 11.48x on LayerNorm.
Analysis
There was no clear evidence of reward hacking in our traces, but Kernelbench references seem to be intentionally naive for more complex operations. We generally followed the guideline here for defensive checks but hope to uncover more pitfalls as part of our efforts. These defensive checks include stream injection detection, thread injection detection, precision downgrade detection, and uses defensive timing – meaning we synchronize GPU operations before recording the end event to ensure all GPU work is completed.
So, who writes the best HIP kernels? Across the board, Opus 4.5, max-thinking and min-thinking both, perform the best. Although GPT 5.2 has relatively low median speedups, it shows the ability to heavily outperform others for certain kernels (specifically attention kernels) although somewhat inconsistent in correctness. Grok and Gemini are consistent, but unexceptional, rarely ever achieving beyond 2x. Kimi K2 and GLM 4.7 consistently struggled to write correct code.
If you find any interesting traces or reward hacks, please let us know! We want to make this the best LLM-generated HIP benchmark.
Final Ranking
| Rank | Model(s) |
|---|---|
| 1st | Opus 4.5 Max / Min |
| 2nd | GPT 5.2 Max / Min |
| 3rd | Gemini Flash / Pro / Grok 4.1 (Tie) |
| 4th | GLM 4.7 Max / Min / Kimi K2 (Tie) |
Interactive Benchmark Results
Explore the full evaluation traces, per-model breakdowns, and individual sample results.

