
Qwen3.6-35B-A3B on AMD MI355X: Being The Fastest With ATOM on AMD
ATOM on 8×MI355X leads public Qwen3.6-35B-A3B on Artificial Analysis decode and sustains ~15k tok/s per node at production latency.

Headline numbers
End-to-end measurement on the ATOM stack we benchmarked. Workload: 10K input / 1.5K output matching Artificial Analysis standards. Streaming with usage-block-authoritative token counting; output length forced via ignore_eos for fair decode comparison.
Source: Artificial Analysis providers page.
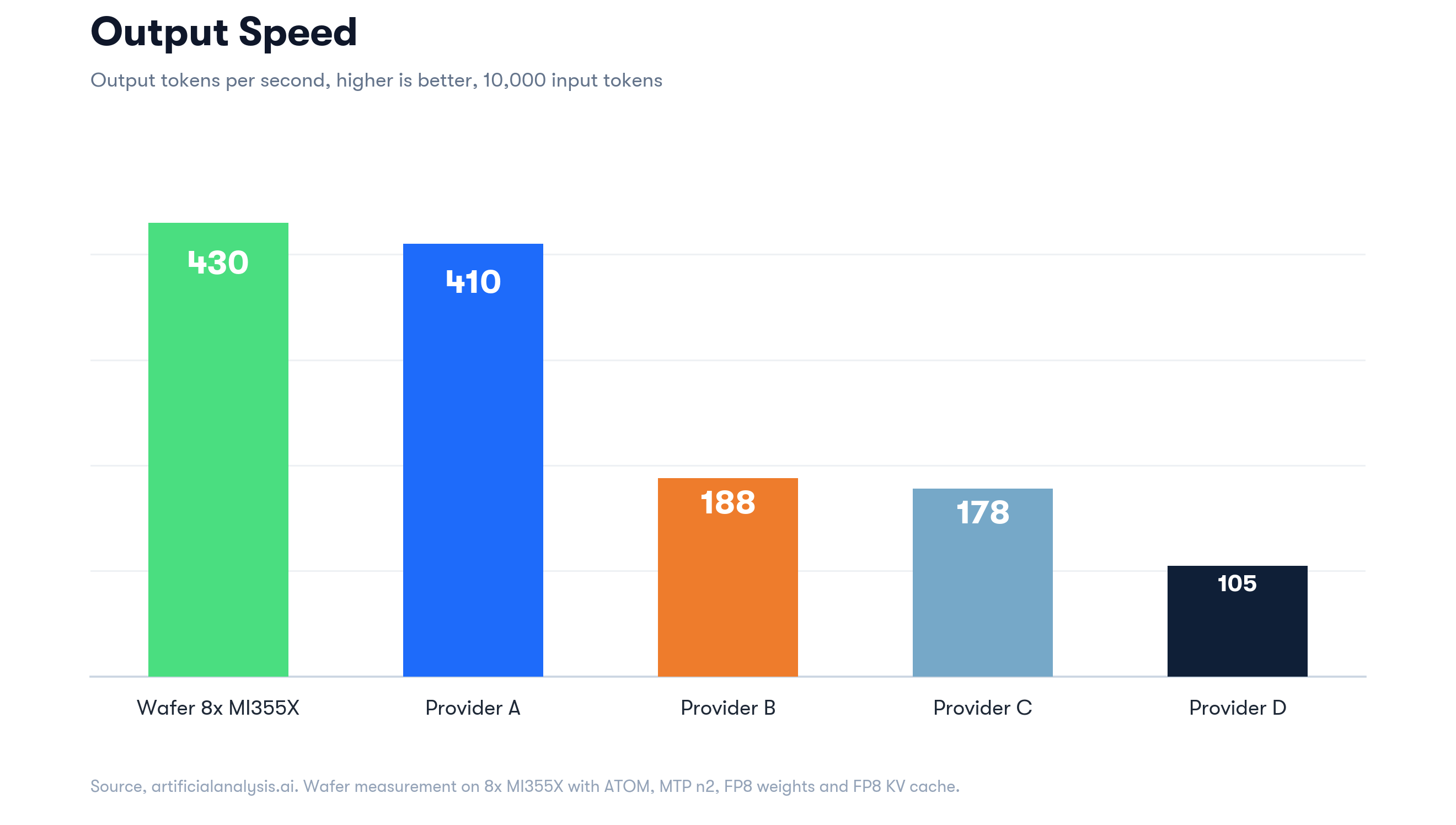
430 tok/s from ATOM is the highest decode rate listed, end-to-end through the full production chain. Provider A is the closest comparable at 402 tok/s. TTFT differences at this scale (337 ms vs 5.5 s) reflect production-stack architecture as much as model serving, so we won’t compare outside of reflecting that we’re confident our TTFT would still be lowest on the list with similar overhead.
Per-node aggregate throughput at production latency
A single 8×MI355X node sustains around 15,000 tok/s of output at TTFT p95 under 4 seconds, roughly 1,873 tok/s per GPU.
| Sustained RPS | Aggregate tok/s | tok/s/GPU | TTFT p50 / p95 | Success |
|---|---|---|---|---|
| 1 | 1,498 | 187 | 333 / 576 ms | 100% |
| 4 | 5,995 | 749 | 239 / 310 ms | 100% |
| 8 | 11,939 | 1,492 | 337 / 1,198 ms | 100% |
| 10 (saturation, p95 < 4s) | 14,986 | 1,873 | 1,904 / 3,636 ms | 100% |
Above RPS=10 the engine continues to accept and process requests without dropping. We measured 100% success all the way through 50 RPS, although above the saturation point TTFT climbs further as the queue grows.
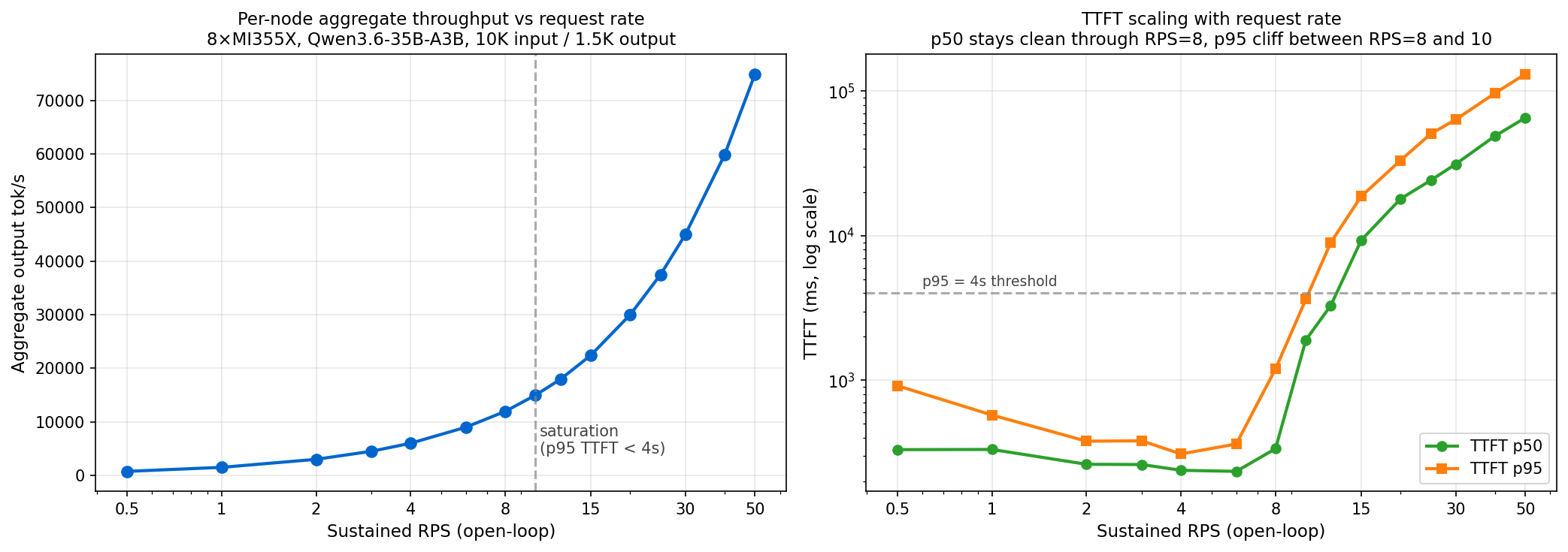
At Provider A’s published single-stream TTFT of 5.5 seconds, the same ATOM deployment reaches roughly RPS=13 (interpolated from our sweep) with around 19,500 tok/s aggregate output, or ~1.6B tokens/day per node.
How we did it
ATOM is AMD’s ROCm-targeted inference engine. It ships with paged attention, continuous batching, FP8 quantization (weights and KV cache), multi-token-prediction speculative decoding, and tensor parallelism, with AITER kernels and ROCm flash attention underneath. Before, “AMD inference” meant fragmented and unreliable support; ATOM is a working foundation today, even if still rough around the edges.
The throughput we measured didn’t come from kernel work or framework patches on our side this time. The decode loop, attention kernels, scheduler, and KV-cache management are all ATOM’s. What we did was identify which combination of ATOM’s existing features produces the best result on MI355X for this model. Wafer’s agent ran a search over the optimization paths ATOM enables.
The configuration:
docker run -d --name qwen36-atom-a \
--device=/dev/kfd --device=/dev/dri --group-add video --shm-size=32g \
-e HIP_VISIBLE_DEVICES=0,1,2,3 -e MASTER_PORT=29500 \
-p 8000:8000 -v /tmp/qwen36-35b-a3b-fp8:/model:ro \
rocm/atom-dev:latest \
python -m atom.entrypoints.openai_server --model /model \
--served-model-name Qwen3.6-35B-A3B \
--tensor-parallel-size 4 --max-model-len 131072 \
--kv_cache_dtype fp8 \
--method mtp --num-speculative-tokens 2 \
--gpu-memory-utilization 0.85Two of these run per node on disjoint GPU sets behind a streaming-aware load balancer. The optimization decisions worth flagging:
TP=4 plus a second replica (DP=2) instead of TP=8
TP=4 plus a second replica (DP=2) doubles the node’s request capacity over a wider TP=8 layout. Qwen3.6-35B-A3B in FP8 (~35 GB) fits comfortably in the 288 GB HBM budget at TP=4, so the extra GPUs are more useful as a second replica than as wider tensor-parallel collectives.
MTP with --num-speculative-tokens 2
Qwen3.6-35B-A3B ships with a built-in MTP head, so --method mtp --num-speculative-tokens 2 lets ATOM propose two tokens per forward pass at no extra decode-step cost, the dominant lever lifting decode throughput from ~190–200 tok/s up to 430.
FP8 weights + FP8 KV cache
We use the official FP8-pre-quantized checkpoint with --kv_cache_dtype fp8. This halves the bandwidth-bound decode-time HBM traffic relative to BF16 and keeps GSM8K at 96.7% (above Qwen’s published 92.7% baseline), matching the AA-listed providers’ precision so the headline comparison stays apples-to-apples.
--max-model-len 131072
--max-model-len 131072 fits a full 128K context window under --gpu-memory-utilization 0.85 thanks to FP8 KV cache and MI355X’s 288 GB HBM headroom, with needle-in-haystack retrieval validated at 4K / 16K / 32K / 64K, and extendable to 256K with a small loss in performance.
Putting it together
MTP drives most of the per-stream tok/s win. TP=4 + DP=2 is the layout that lets us use the full 8-GPU node without paying for wider tensor-parallel collectives. FP8 quantization halves memory bandwidth on the bandwidth-bound decode path. 128K context comes free under FP8 KV at MI355X’s HBM budget. The numbers are an interaction of all four; ATOM exposes each as a flag, and the configuration converged here is what the Wafer agent found to best fit our specific use case.
Hardware baseline
The realistic NVIDIA inference-class set we compare against is H200, B200, and B300. AA doesn’t disclose per-provider hardware, but other providers likely span B200 / B300 with some H200 still in service.
| Spec | AMD Instinct MI355X | NVIDIA B200 | NVIDIA B300 (Blackwell Ultra) |
|---|---|---|---|
| Architecture | CDNA 4 (gfx950) | Blackwell | Blackwell Ultra |
| HBM capacity per GPU | 288 GB HBM3e | 192 GB HBM3e | 288 GB HBM3e |
| HBM bandwidth per GPU | 8 TB/s | 8 TB/s | 8 TB/s |
| TDP | 1400 W | 1000 W | 1400 W |
| Per-node (8×) HBM | 2.3 TB | 1.5 TB | 2.3 TB |
Sources: AMD Instinct MI355X GPUs, AMD MI355X product brief PDF, NVIDIA DGX B200 datasheet, Tom’s Hardware B300 announcement.
For the inference workload here, what matters is HBM capacity and bandwidth. Decode-time throughput on this model is bandwidth-bound, since each step touches only the routed experts (~3B active params) and reads weight and KV-cache traffic from HBM. Bandwidth is at parity across all three. HBM capacity matters for batch capacity, context length, and quantization headroom: MI355X and B300 have 288 GB, while B200 has 192 GB and is very hard to fully utilize when serving inference.
For this workload class, compute isn’t the bottleneck; using HBM efficiently and maximizing utilization throughout inference is.
Pricing, May 2026
| Hardware | Source | $/GPU/hr (median) |
|---|---|---|
| MI355X | GPUs.io | $2.29 – $2.95 |
| B200 | GPUs.io | $5.28 |
| B300 | GPUs.io | $6.19 |
Other sources: GetDeploying, Ornn B200 (May 2026).
The AMD rental market is thinner than NVIDIA’s, with far fewer providers than against the Blackwell counterparts. Some of MI355X’s pricing edge reflects thinner demand rather than structural cost advantage, and we expect it to compress as AMD adoption grows. Even so, MI355X bare-metal quoted up to ~$2.95/GPU/hr (the upper end of the May 2026 range snapshot above) is meaningfully cheaper than both B200 and B300 at the same terms.
Token economics
Working backwards from measured aggregate throughput and that ~$2.95/GPU/hr MI355X ceiling from the pricing table:
- Per-node sustained output at servable saturation: ~15,000 tok/s (TTFT p95 under 4 s, 100% success)
- Per-node hourly cost: 8 × $2.95 = $23.60/hr
- Per-node hourly output at saturation: 15,000 × 3,600 = ~54M output tokens
- Implied COGS (cost of goods sold: GPU-hours at the hourly rate above, before margin or overhead): ~$0.44 per 1M output tokens
For comparison, the AA-published list prices on Qwen3.6-35B-A3B (output, $/1M tokens):
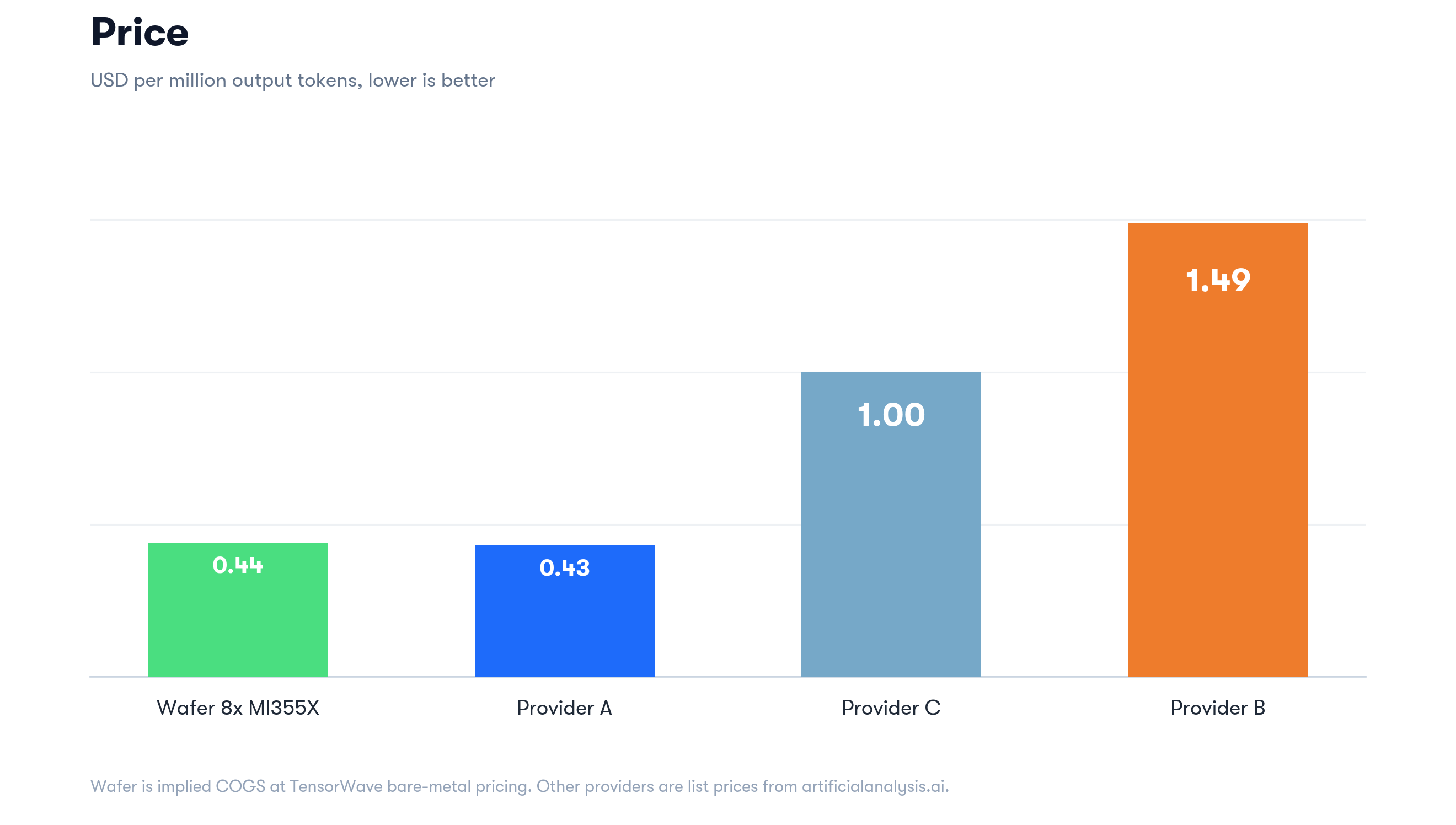
Worth flagging: AA list prices include each provider’s margin and overhead without accounting for input $/M, which is typically served at 1/10× to 1/5× of the output token cost.
Why this matters
Two things are worth landing.
First, the immediate one. ATOM gives AMD a working foundation for modern MoE inference, and MI355X running ATOM is competitive with Blackwell-class hardware on the workloads we measured. With Blackwell still in short supply and clear headroom for software and perf engineering to close the rest of the gap, AMD looks ready to provide a reliable alternative for high-performance inference. We acknowledge that this study doesn’t take multi-node performance into consideration; that said, single-node deployments still remain highly prevalent in practice.
Second, the broader one. Alternative hardware gets more useful in the age of agents, on both sides of the deployment. On the user side, config sweeps and profiler-driven optimization that used to require a kernel dev to commit weeks to a new platform compress significantly with an agent in the loop; the cost of evaluating and committing to alternative silicon drops. On the hardware-vendor side, the same dynamic keeps the inference engine itself competitive: the porting and kernel-tuning work that landed ATOM and the AITER backends in upstream vLLM is exactly the shape of work that compresses well under agentic tooling.
Both effects compound. As more of the work on both sides moves under that pattern, the friction that kept inference de facto NVIDIA-only erodes from both ends. The hardware-cost and hardware-availability arguments for alternative silicon start translating into actual deployments. This post is one data point, and the pattern will keep playing out.
Enterprise
If you’d like us to serve this as a dedicated endpoint for your use case, contact hi@wafer.ai for a demo.

