
How Neon Health Cut Voice-Agent TTFT From 800 ms to 550 ms on Wafer
- GLM-5.1
- Served on a dedicated Wafer endpoint
- ~550 ms
- Client-observed p50 TTFT, down from the prior provider's 800 ms
- -30%
- p50 TTFT at ~25% higher peak load
- Dedicated endpoint
- TTFT-based SLA
- Signed BAA · US-only
Overview
Neon Health runs HIPAA-compliant voice agents for healthcare. By moving GLM-5.1 inference to a dedicated Wafer endpoint, the team cut client-observed p50 time-to-first-token by roughly 30% — at ~25% higher peak load than its previous dedicated deployment — with that target now written into the SLA.
At a glance
- Industry
- Healthcare — AI-powered patient access for pharma programs
- Use case
- Real-time voice agents for payer, provider, and patient phone calls
- Model
- GLM-5.1
- Wafer product
- Dedicated inference endpoint with a TTFT-based SLA
- Compliance
- Signed BAA, US-only data residency, zero data retention
About Neon Health
Roughly 25% of US healthcare spend goes to administrative activities — phone calls, faxes, portal lookups, status checks. About a quarter of every dollar spent in healthcare goes to tasks that don’t directly benefit the patient.
Neon Health builds AI workers that take this work off humans for pharmaceutical patient-access programs, automating benefit verification, prior authorization, and financial-assistance enrollment end to end. Neon’s voice agents place calls to payers, providers, and patients, and automate up to 98% of them without human intervention. Neon made millions of phone calls last year.
What makes Neon’s serving problem unique and difficult is that response times have to be ultra-low-latency to support natural, multi-turn interaction with the person on the line. Some requests are heavy and require information gathering, so every layer of the stack has to be optimized for real-time latency.
The challenge: a phone call is a real-time deadline
Neon budgets 800 ms from the end of user speech to first agent audio. Past that, the call stops feeling like a conversation — and because speech recognition and text-to-speech also consume the budget, the LLM only gets what’s left. The target Neon set for Wafer: TTFT at or below 600 ms, as observed from Neon’s own infrastructure.

“Any more than that and you start breaking the flow of the conversation. You never have a delay like that when talking to a human, and we are fundamentally social creatures — so we pick up on things like that very quickly.”
Compliance
Every call touches PHI. The first question Neon asked Wafer was: “Before we move any further, do you have a BAA you can sign?” US-only data residency was equally non-negotiable.
Reliability
A previous inference provider gave Neon a verbal capacity commitment, then pulled it to serve larger customers right before a launch. Neon was shopping for a partner it could trust long-term.
What Neon ran before
Neon built its MVP on closed-source frontier APIs. Model intelligence met the bar, but latency didn’t. Neon maxed out the rate limits on the providers’ highest tiers, and shared-pool variance meant a system that benchmarked well at midnight ran up to 4× slower during business hours, when most calls come in.
A managed deployment on a hyperscaler’s accelerators followed, but it couldn’t guarantee latency or dedicated capacity. Neon then moved to open weights on a dedicated deployment with another inference provider. That was production-viable — about 800 ms p50 / 1,300 ms p90 client-observed TTFT at ~400 requests per minute — but the LLM alone was consuming the entire conversational-turn budget.
The solution
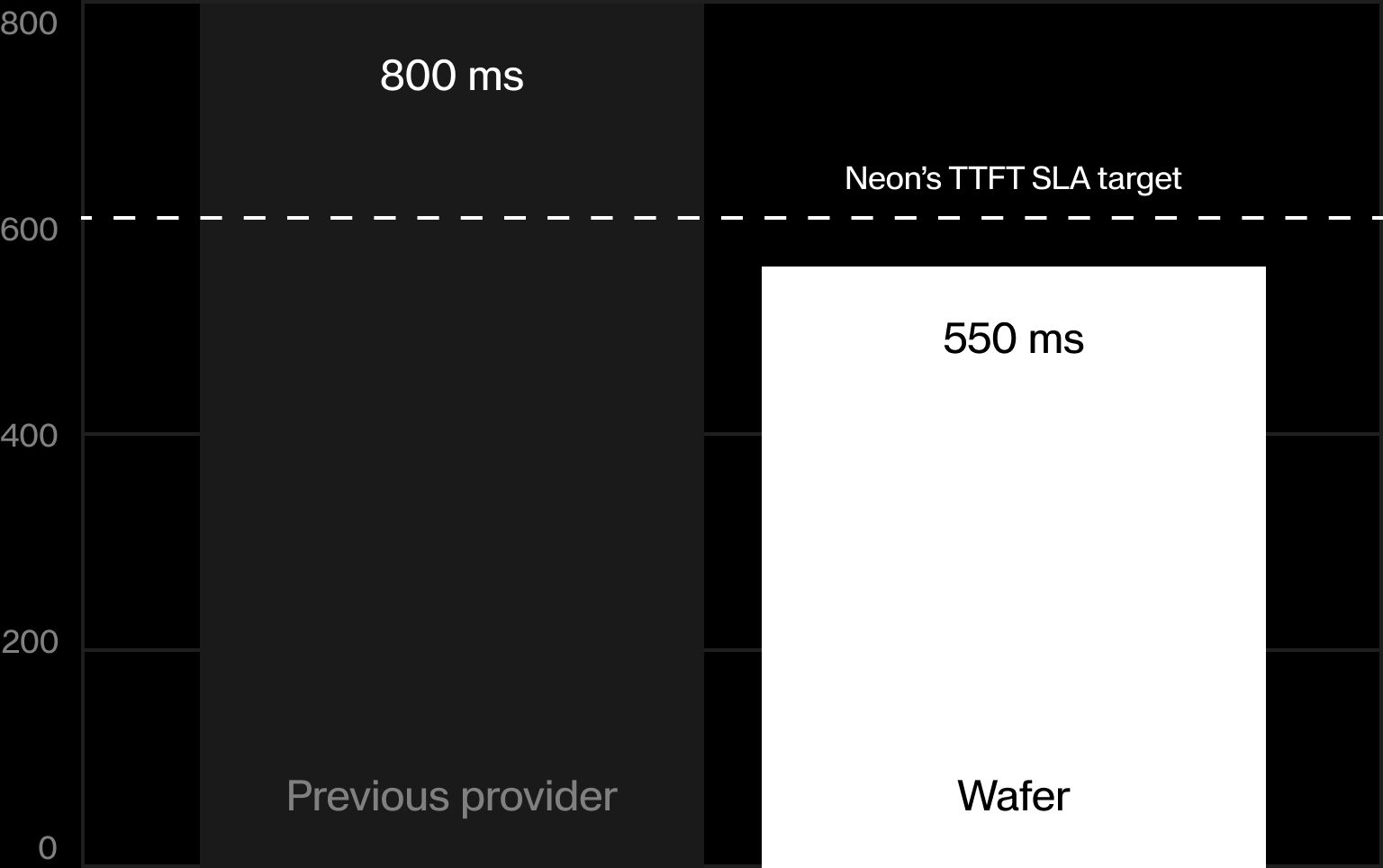
Client-observed p50 TTFT cut from 800 ms to ~550 ms
Neon Health’s own measurement after moving GLM-5.1 to a dedicated Wafer endpoint — at ~25% higher peak load.
What changed
Same model, faster serving — GLM-5.1 on a dedicated, TTFT-tuned Wafer stack
Headroom under the wall — ~250 ms of the 800 ms turn budget freed up
Inside the SLA — TTFT now sits below the 600 ms target Neon set
The fix: a TTFT-first serving stack
Wafer benchmarked Neon’s exact traffic shape — long cached prompts, short outputs, business-hours bursts. From there, Wafer’s forward-deployed engineers, alongside the autonomous performance-engineering agent, swept configs and implemented custom kernels. The team also quantized GLM-5.1 while passing Neon’s quality evals — in Neon’s words, with better results than other quantized models they’d seen.
-
Cache-aware routing
With a cache-hit rate above 95%, routing is the unassuming backbone. Each call’s growing context lands back on the replica that already holds its KV, so the cost is mostly the new incoming tokens.
-
Chunked prefill + custom kernels
Chunked prefill keeps one long prompt from stalling admission for everyone else, with custom kernels on the GEMM and MoE paths.
-
Stepped decode over speculative decoding
Speculative decoding was tested and rejected — TTFT became unstable under bursts. Short decode steps won instead: between steps the scheduler admits newly arrived prefills, which holds TTFT down when twenty requests land in a 100 ms window from an auto-dialer.
-
Throughput left on the table
Per-stream decode speed is tuned below what the hardware can do, in exchange for stable TTFT and low inter-token jitter — smooth text-to-speech matters more than tokens per second nobody hears.
Latency that doesn’t fall off a cliff
p50 TTFT barely moves as sustained load climbs — where the previous dedicated provider and shared-pool APIs curve up and off the chart.
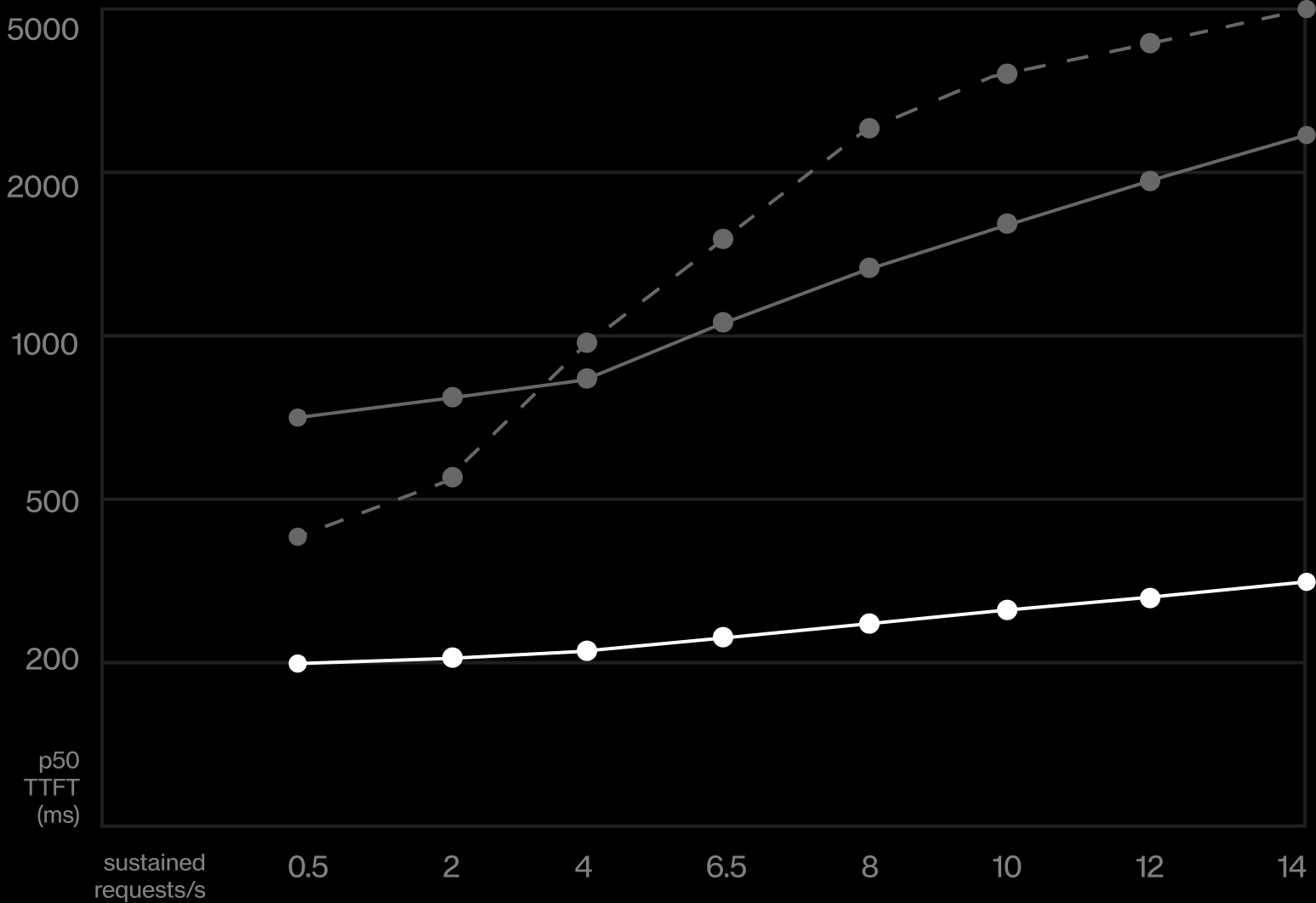
- Wafer dedicated endpoint
- Previous provider (dedicated)
- Shared-pool / closed API
Measured from US-West clients: 237 ms p50 / 502 ms p90 TTFT at a sustained 6.5 requests per second on ~20k-token prompts.
Forward-deployed inference engineering
The deployment model matters as much as the serving config. From the first call, Neon has worked in a shared Slack channel with the entire Wafer team — benchmark ladders, serving configs, and root-cause analyses get posted there directly. When the node began approaching its serviceable headroom during peak hours, Wafer flagged it and proposed the scaling path.
“I really appreciate when the vendors we work with are proactive in their outreach, their suggestions, and their recommendations — rather than being reactive, or not reactive at all. It feels like a collaboration, rather than: here’s the menu, don’t talk to us.”
Because of Wafer’s white-glove, forward-deployed approach, Neon’s endpoint went from benchmark kickoff to production traffic in under two weeks — at the best performance in the market for their needs.
“The performance we’re getting on the models we benchmarked was way better on Wafer than on other inference providers. You have the lowest latency we’ve seen from any provider we’ve tried, and it doesn’t go off a cliff when you increase the requests per minute. We get very consistent performance across our expected utilization range.”
“It feels like a collaboration. It’s great to see a dedicated group of people pushing hard to support our needs, all while delivering exceptional performance on all of the hard engineering metrics that we require.”
Harry Bleyan
Co-founder & CTO, Neon Health
Why this matters
Few environments are as demanding as voice in LLM serving. The 800 ms limit for natural conversation is a fixed constraint that forces optimization across the full serving stack. Hitting it took a series of practical, high-impact choices:
- Selecting an open-weights model and quantization that satisfied rigorous internal evals
- Strategic node placement
- Cache-aware routing that achieved a 95%+ hit rate
- Custom kernel and low-level optimization work at the runtime level
- Prioritizing variance reduction over peak throughput in decode scheduling
- Maintaining a transparent view of the entire network path between the server and the end user
Your voice agents live or die
on latency
Wafer measures your traffic, optimizes a dedicated endpoint for your TTFT SLA, and gets you to production in under two weeks — without crashing during call-volume spikes.
Signed BAA · US-only data residency · TTFT written into the SLA