
Achieving Heterogeneous Compute One Kernel at a Time
How custom kernels pushed our AMD MI355X deployment from a tuned baseline to leading Qwen3.5 397B throughput.

Performance vs. Price: Why Not Both?
Often, the discussion surrounding alternative hardware for serving inference is centered around the tradeoff between performance and price. AMD MI355X GPUs are much cheaper than NVIDIA Blackwells, around 2.5x cheaper per GPU on average. Although the hardware specs are comparable, the maturity of the NVIDIA GPU software ecosystem typically allows providers to serve inference much faster on NVIDIA hardware.
But software maturity is a fragile advantage, one that is disappearing as agents improve at kernel and end-to-end model optimization.
Case in point: we achieved 310 tok/s for Qwen3.5 397B A17B on 10k input tokens / 1.5k output tokens, following Artificial Analysis standards, served on AMD MI355X capacity from TensorWave. This number beats every other provider on Artificial Analysis, proving that AMD can compete on both performance and price.
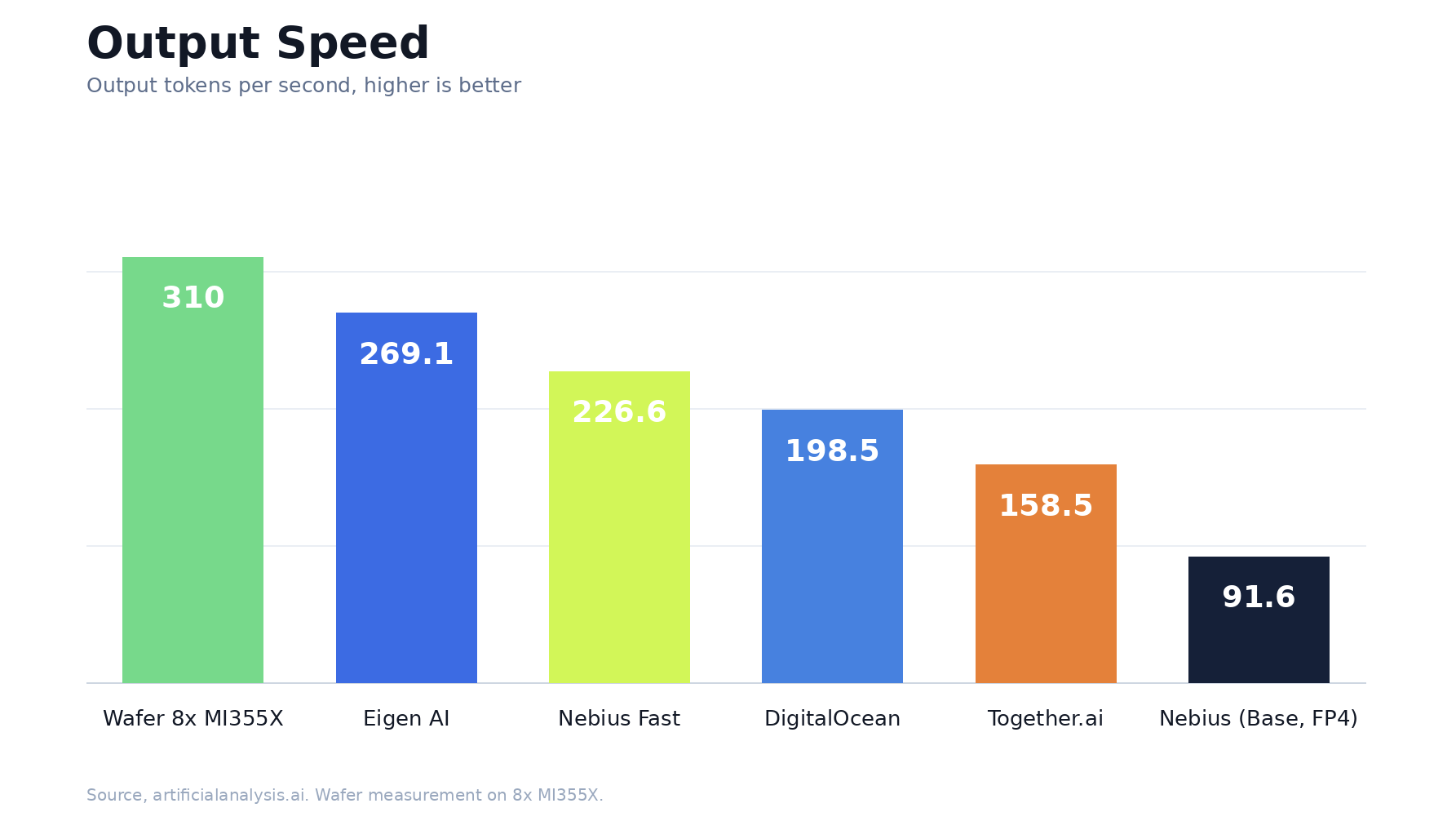
We saw in the previous Qwen3.6-35B post that SOTA performance could, in fact, come out of the box on AMD hardware with some parameter tuning. This hyperparameter tuning is often where most folks stop before hosting models.
This was not the case for Qwen3.5 397B. To achieve these large performance gains, we squeezed as much as we could out of the engine hyperparameters, then dove into writing custom kernels for the specific workload, walking away with a 20% faster model over the tuned baseline and a 15.2% faster model than the previous top provider on Artificial Analysis.
Our optimization methodology is as follows.
Preliminary Optimizations: Multi-Token Prediction + Quantization
It all started with the inference engine and the weight format for the model.
We chose to use ATOM, AMD’s inference engine specifically optimized around AMD’s AITER library, along with MXFP4 quantized weights for the Qwen model. We also applied FP8 quantization to the KV cache and enabled speculative decode. Out of the box, this combination gave us the strongest decode performance while maintaining coherent model output. vLLM and SGLang were both considered, but fell short of ATOM in decode tok/s.
Once we decided on the stack, sweeps through ATOM launch configurations allowed us to achieve 260 decode tok/s. These configs include, but are not limited to, FP8 KV cache and MTP-3. But this number was still below what we were aiming for: #1 on Artificial Analysis. The remaining levers would have to come from kernel-level optimizations, the task our Wafer agent is built to specialize in.
The real fun began.
Kernel Optimization 1: MoE GEMM
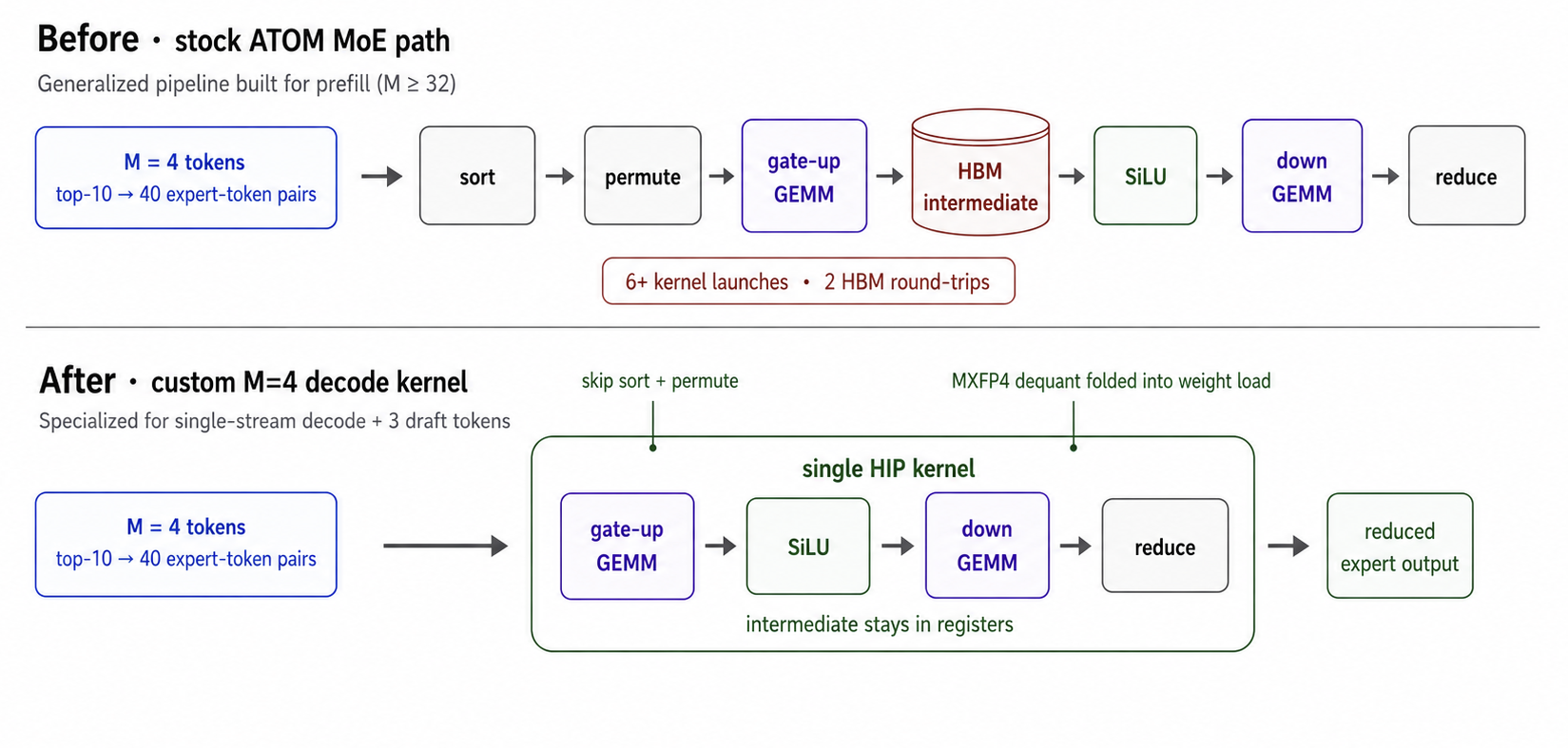
With our agent, we built a custom MoE GEMM kernel at M=4, optimized for single-stream decode plus three draft tokens. ATOM’s stock MoE is generalized but tailored to prefill batches of 32+ tokens, where you have enough work per expert to amortize the cost of dispatching 6+ kernels and 2 full HBM roundtrips.
Those kernels sort tokens by expert, permute activations into expert-grouped order, run the gate-up GEMM, write the intermediate activation to HBM, run SiLU, read it back, run the down GEMM, and finally reduce.
But each MoE call at MTP-3 single-stream decode processes only 4 tokens, making most of those kernels redundant or pure overhead. With top-10 routing on 512 experts, that is only 40 active expert-token pairs per step. The sort+permute chain is mostly empty work, the CK FlatMM tile is >=87.5% under-utilized in the M dimension on every active expert, and you pay full launch plus HBM cost for kernels that have nothing to amortize against.
We replaced the routed-expert dispatch with a single HIP kernel specialized for our decode shape, skipping the sort and permute entirely, and fusing the gate-up GEMM, SiLU, and down GEMM into one kernel. We also fold MXFP4 dequantization into the weight load so the intermediate activation never has to leave registers.
The MXFP4 scale tables ship in a 3D shuffled layout that interleaves exponents in 32-element micro-groups, laid out for the stock CK kernel to stream alongside its weight tiles. Our kernel walks weights in a different order, so at load time we unshuffle once into a flat layout and keep both copies resident. Stock reads the shuffled one for prefill, ours reads the flat one for decode. Inside the kernel, each FP4 tile is scaled as it streams into LDS. No separate dequant pass, no BF16 intermediate weight tensor.
This creates slightly more memory pressure, but the model sits comfortably in memory at TP=8, so this is a non-issue.
6 launches -> 1, zero intermediate HBM roundtrips. The result: 1.84x faster per MoE call and +30-40 tok/s end-to-end, allowing us to hit 300 tok/s on the MI355X node.
Kernel Optimization 2: Fusion Galore
The next kernel-level optimization targeted a more obvious naivety in ATOM. Before each Qwen3.5 MoE layer reaches the routed-expert dispatch, it runs two GEMMs from the same input tensor: one to produce the router logits, which decide which experts each token goes to, and one to produce the gate-up projection for the always-on shared expert.
ATOM dispatches them as two separate kernel launches, which means two HBM reads on the exact same hidden_states tensor and two graph nodes in the captured graph.
We fuse them into one GEMM. The router weight is [K=4096, N=513], replicated across ranks since the gate is not TP-sharded: 512 routed experts plus 1 shared expert. The shared expert’s gate_up_proj is [K=4096, N=2048] full, with gate and up concatenated, each 1024 wide. Column-sharded TP=8 gives 256 columns per rank. Concatenated along N, this is a [K=4096, N=769] GEMM that produces both outputs side by side.
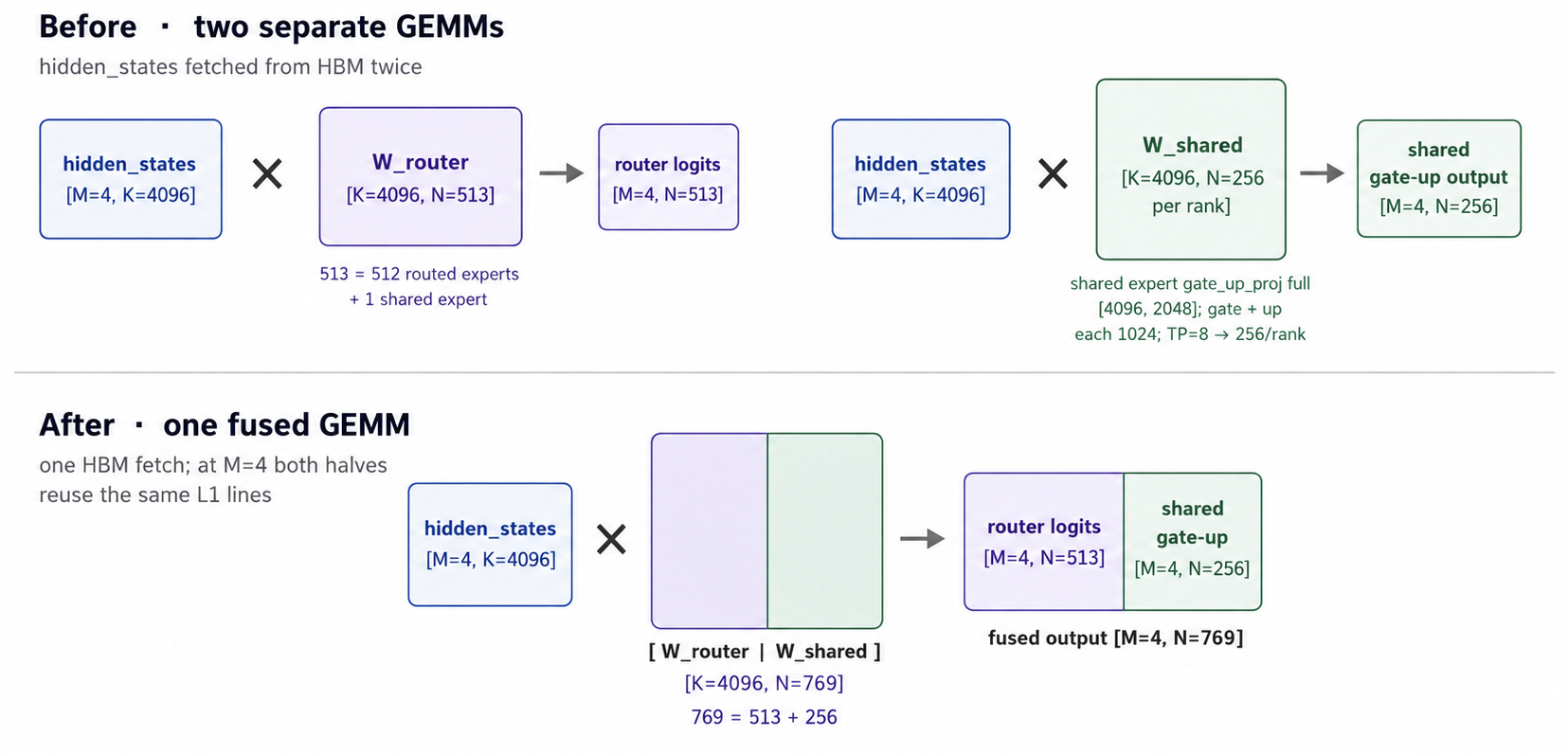
At M=4, the input is small enough that the two halves share L1 lines, so we get a single cached read of hidden_states across both halves on top of the one-launch savings. With this fusion and our custom MoE kernel at M=4, our Qwen3.5 397B was running at 310-320 tok/s on MI355X, comfortably ahead of anyone on Artificial Analysis.
Making It Production-Ready: Prefix Caching
Most of our work focused on optimizing decode tok/s, but output throughput is not the only thing that matters in production. TTFT is equally important for serving inference, and often what customers feel the most.
Getting the ATOM + Qwen3.5 stack to a servable TTFT was non-trivial because ATOM’s prefix cache implementation is broken for Qwen3.5. Qwen3.5 is a hybrid model with 15 full-attention layers and 45 GDN linear-attention layers. The 45 GDN layers carry a per-sequence recurrent hidden state that lives outside the paged-attention KV cache. ATOM’s scheduler had no awareness of it.
Without explicit caching of that state, every chunked-prefill step would recompute the GDN recurrence from scratch. On a prefix-cache hit, the cached KV would no longer match the recomputed hidden state. The result was coherent but non-deterministic output, even at temperature=0.
The fix was clear: we had to build the Mamba-state cache. The recurrent state for each sequence gets snapshotted alongside its KV blocks and invalidated together on prefix-cache hits and evictions.
Prefix caching massively speeds up TTFT for requests that share a prefix. At our production cache-hit rate of 89-99% above 16k ISL, this is a massive difference. We also fixed a mathematical error in ATOM’s chunked-prefill token slicing that caused non-deterministic output at temperature=0 and degraded accuracy.
With deterministic output and proper prefix caching, Qwen3.5 397B on ATOM was finally both fast at 310 tok/s and servable with good TTFT.
| ISL | TTFT without prefix caching | TTFT with prefix caching | Speedup |
|---|---|---|---|
| 16k | 37.7 s | 150 ms | 250x |
| 50k | 32 s | 190 ms | 170x |
| 100k | 50 s | 428 ms | 115x |
| 196k | 110 s | 730 ms | 150x |
Takeaways
This work lends itself to a few conclusions.
- MI355X can compete with and outperform Blackwells. Though the raw specs have always been up to par, it is promising to finally see SOTA performance achieved on the MI355X for a model as popular as Qwen3.5 397B.
- Day-zero support is still NVIDIA-native. Features like prefix caching require non-trivial custom work to implement on AMD today. This is where we feel the software ecosystem maturity gap the most.
- The advent of agentic model optimization is here. Wafer’s agent is able to find optimal launch configs and inference frameworks, identify bottleneck kernels, and optimize them to achieve significant performance gains on SOTA models, shortening a process that would normally take months to a matter of days.
Our agent-driven optimizations allow us to achieve the results above, and to serve models like GLM5.1 at 200+ tok/s for thousands of users.
TLDR: Qwen3.5 397B MXFP4 on ATOM with optimal configs + a custom MoE kernel + a router-fusion GEMM + Mamba-state cache -> p50 310 tok/s, netting us #1 on Artificial Analysis using MI355X.

